El trabajo, en orden cronológico, ha sido aproximadamente así (sin fechas ya que no tengo forma de recuperarlas):
1 - Introducción al uso de ROOT y c++. Esto fue comenzar desde cero ya que nunca había usado dicho lenguaje, mucho menos ROOT. Hubo que entender sintaxis, estructura básica de un programa:
- encabezados
- variables globales
- lectura de archivo(s)
- main
y definiciones específicas de ROOT, como por ejemplo TCanvas, fill(), Draw(), etcétera. Para todo ello fueron auxiliares los manuales de ROOT, su foro (roottalk), sitios como stackoverflow y mucha ayuda personal (del Dr Ricardo López y mi compañero Israel Huerta principalmente), y claro, mucho ensayo y error.
2 -Una vez entendido cómo debe estructurarse un programa sencillo en ROOT, pasamos a la elaboración de gráficas sencillas, lo que implica entender el uso e implementación de las mismas, con énfasis en los histogramas. Abajo muestro una de las primeras gráficas elaboradas, a partir
de las diferencias,
no de los precios absolutos, llamadas
retornos:
Se implementó el archivo que lee los datos de algún índice financiero (Nasdaq en la gráfica), calcula sus diferencias, y las grafica, en escalas normales. Posteriormente se usaría escala log-normal para ver las colas pesadas, esto es, extremos donde la gráfica se desvía de una distribución gaussiana.
3 - Implementación de rutinas simples para análisis de datos (obtener diferencias y graficarlas, básicamente). Aquí se usó ya la superposición de las mismas y detalles como el uso de "stat box".
El proceso fue básicamente el mismo que antes, pero se requirió averiguar cómo superponer histogramas, diferenciarlos, y cómo presentar más de una gráfica en la misma ventana. Nótese que se presenta ya con escala log-normal y se aprecian las colas pesadas en los extremos.
4 - Obtención de archivos ROOT. Esto, con el propósito de poder usar más adelante las diversas características de los mismos.
5 - Obtención de índices financieros diferentes, eso incluye buscar las fuentes adecuadas, comparación de las mismas, "limpieza" y rehacer cálculos.
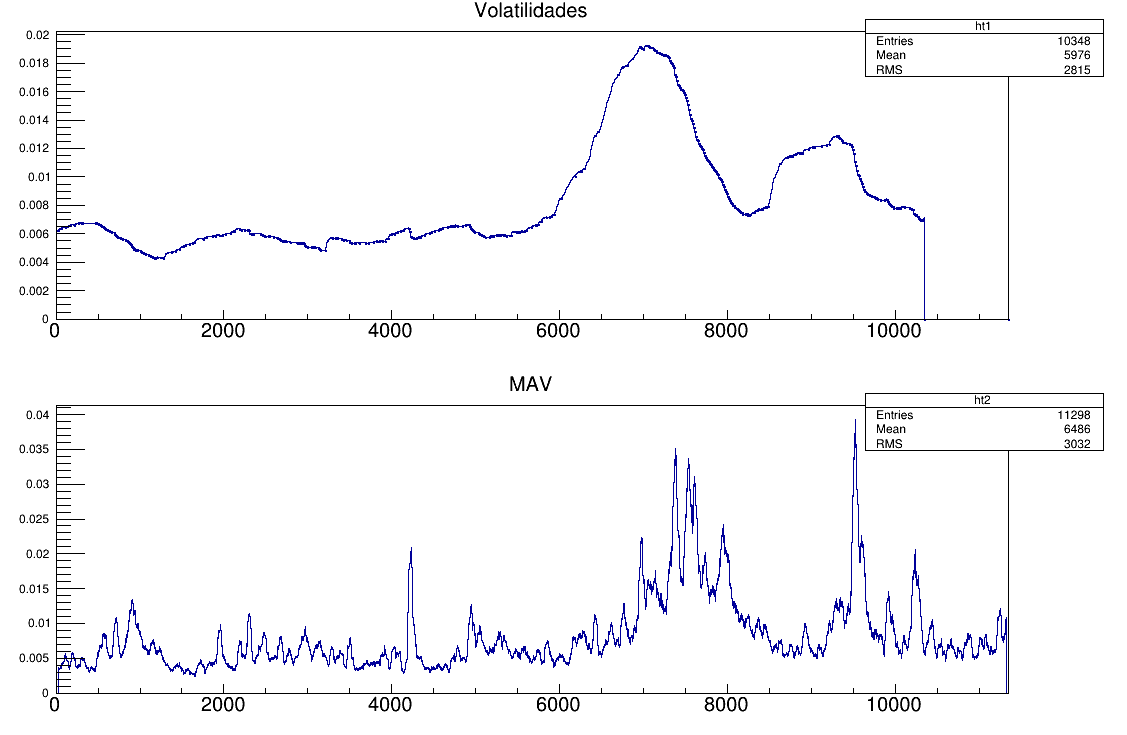
6 - Implementación de volatilidad y desviación estándar (intentamos obtener el cálculo mediante las fórmulas del libro "The statistical mechanics of financial markets", de J. Voit). Esto fue una labor ardua debido a la poca información acerca del cálculo original. Al final, excepto por la normalización, era prácticamente lo mismo.
en la gráfica de arriba se generan números aleatoriamente de una distribución gaussiana y se calcula su desviación estándar de forma aproximada al libro mencionado, incorporando un eje temporal(archivo desv_est3.C). Se podía notar una estructura cuasi aleatoria, sin embargo no proporcionaba los resultados esperados. Se procedió a calcular las volatilidades. Esto dio como resultado:
Este macro dividió los datos en "trozos" de 30, y para cada uno de ellos obtuvo su media y RMS, repitiéndolo 170 veces.
Dada la discrepacia entre los métodos para calcular la autocorrelación, se probó a comparar el método ya existente con otro similar al del libro mencionado. Los resultados fueron (archivo doubletrouble.C):
La primera imagen (de arriba hacia abajo) corresponde al índice. La segunda, a las diferencias, la tercera a la autocorrelación según el método inicial, y la cuarta según el método "modificado" (es decir, similar al usado en el libro de Voit). Puede verse que no hay diferencia esencial y el método elaborado es más sencillo e intuitivo.
También puede verse que existe un problema de normalización, el cual quedó pendiente (lo hice en un archivo que por el momento no hallo, sin embargo ocurrió el problema inverso, aparentemente quedaron muy pequeñas).
7- Primer borrador de tesis. La estructura fue fijada por Raúl, y acorde con ella se hizo. Este primer borrador incluyó una introduccción a los temas tratados: sistemas complejos, econofísica, mercados financieros, etcétera).
8 - Segundo borrador de tesis. Con correcciones sugeridas por Raúl y Ricardo.
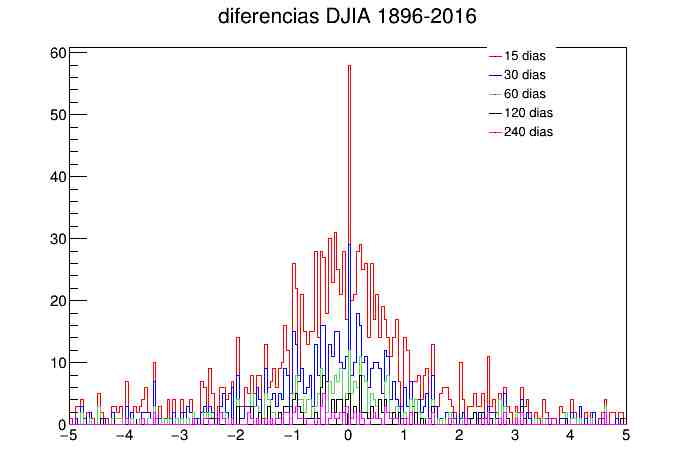
9 - Intento de visualización de leyes de potencia dentro de los retornos a diferentes tiempos. Esto se ha hecho de manera burda con los siguientes resultados:
Aquí se ha tomado un índice y se han calculado sus retornos a 14, 30, 60, 120 y 240 días. Posteriormente, se han obtenido sus máximos y se han graficado en un diagrama log-log:
La idea central es que con diversos "lags" aparecerá una ley de potencias, que es la marca de sistemas complejos, por lo cual a partir de ahí se podrían usar ciertas analogías ya existentes o estudiadas.
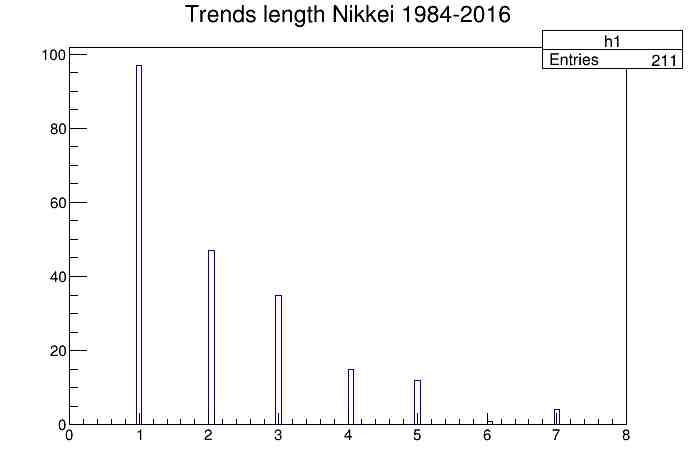
10- Distribución de longitudes de trends. Una vez obtenidas las distribuciones y la manera en cómo se comportan bajo diferentes intervalos, pasamos a analizar los segmentos o
trends. Lo primero era graficar los datos y obtener dichos trends. Hecho esto se procedió a elaborar un histograma de la frecuencia de su longitud:
como era de esperar, los trends cortos predominan, esto significa que los cambios pequeños predominan, y cambios "sostenidos" son raros.
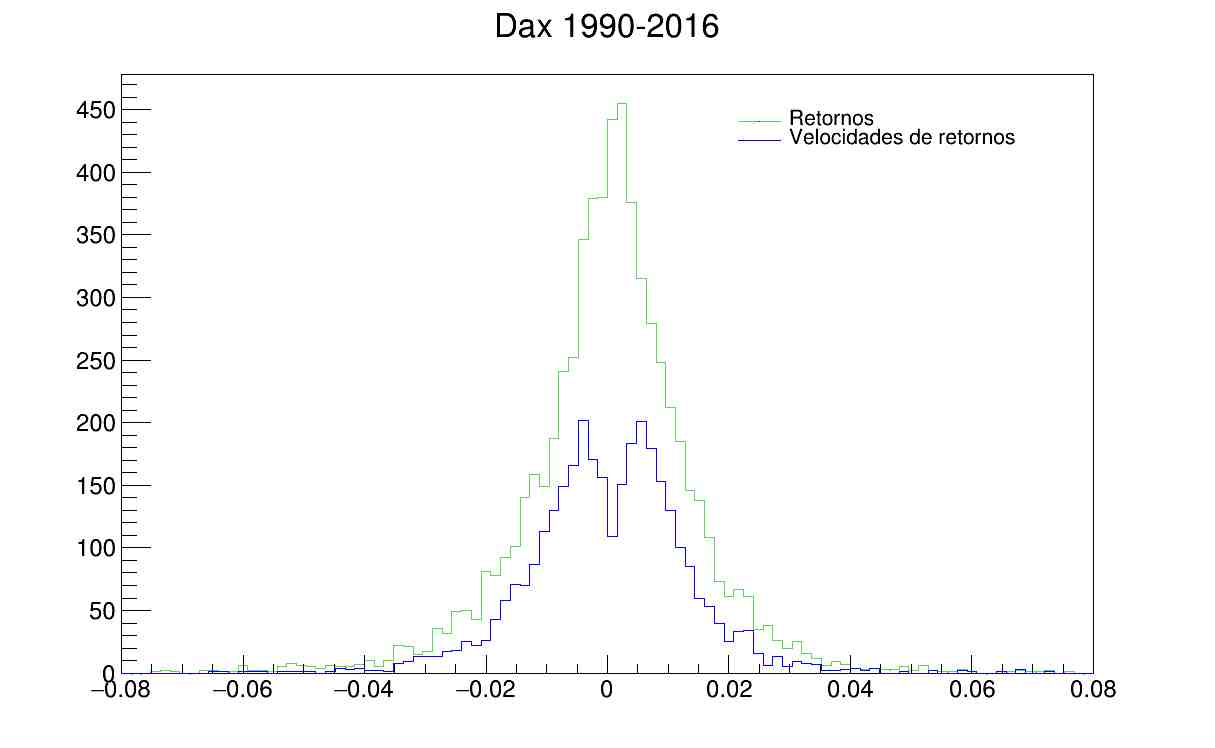
11- Procedemos a calcular retornos y velocidades de diferentes índices:
12- También se calculan las distribuciones de los retornos y velocidades:
es notable la existencia de dos "picos" en la distribución de velocidades, por lo cual procedemos a graficar la distribución por separado de las velocidades negativas y positivas: